Wikidata:WikidataCon 2017/Notes/Inventaire: tale of a Wikidata-centered linked open contributive database on resources/books
Title: Inventaire: tale of a Wikidata-centered linked open contributive database on resources
Note-taker(s): User:Gikü
Speaker(s)[edit]
Name or username: Maxime Lathuilière (User:Maxlath)
Contact (email, Twitter, etc.): max@maxlath.eu - @maxlath
- Useful links
- https://inventaire.io/welcome
- https://wiki.inventaire.io
- http://dumps.inventaire.io
- https://git.inventaire.io
- https://github.com/inventaire//wikidata-subset-search-engine
- https://api.inventaire.io/
- https://query.inventaire.io (coming soon)
Abstract[edit]



- vision: mapping resources with libre software and knowledge
- general overview of the inventaire.io server (Q32844021) service: a web app to keep inventories of books using Wikidata
- digging on the data:
- data sources and assisted/semi-automated data contribution
- data structure: URI-based Wikidata-mimicking data schema (labels, claims), but simplified and more strongly constrained to make edition easier by anyone
- the entity editor
- editing Wikidata from Inventaire
- use of Inventaire data out of the book sharing service: api.inventaire.io
- next steps:
- extending Wikidata role of identifier hub to entities not known by Wikidata, using libraries identifiers (SUDOC, BNF, BNB, etc)
- Inventaire Game/Mix-&-Match
- first dump once tools are in place and data has a lower amount of duplicates
Collaborative notes of the session[edit]
inventaire.io - pretty much a books inventaire and book sharing software. Notable to WD because it uses and refers to Wikidata.
- 2 pillars
- book sharing webapp
- open data
Mission: linking free software w/ open software
Background on the organization itself: 3 years old, strives toward a non profit structure
History in 5 seconds: inventaire.io was connected to wikidata in 2016, extended its API in 2017
It is planned to extend SPARQL implementation in 2017, connect libraries in 2018, and make Amazon go bankrupt by 2021
Maxime demoes the webapp itself, then goes to what is under the hood
inventaire.io is based on entities (authors, series, subjects, works, editions etc.) Wikidata helps with most of them
inventaire data model : https://raw.githubusercontent.com/inventaire/entities-map/master/screenshots/entities-map.png
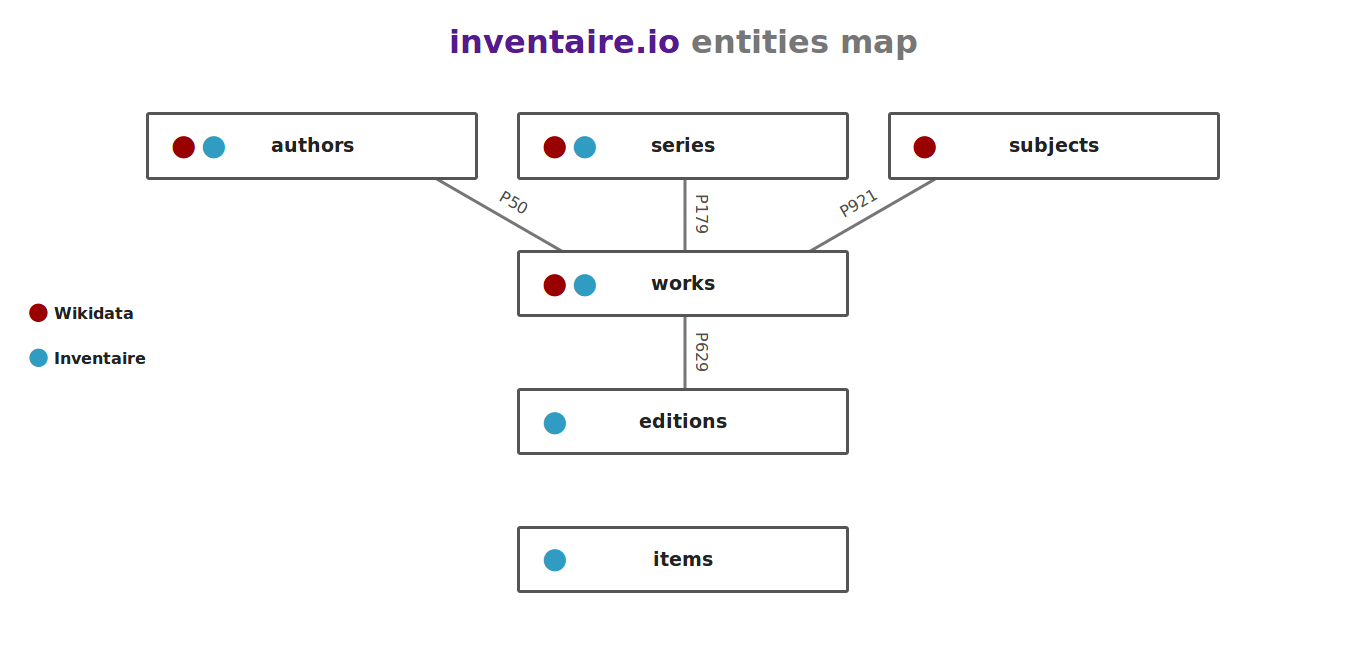{kind=link}
inventaire.io does not rely entirely on WD, it has an internal data edit feature, although the edit feature is inspirred from WD, and partially uses it (e.g. language, genre)
URi structure mimicks Wikidata. Same with JSON outputs
items architecture refers to WD with labels & claims
RDF (Resource Description Framework) is supported (Turtle exports available at dumps.inventaire.io)
soon available: federated query on query.inventaire.io
- Maxime's vision
- Wikidata should serve as the common vocabulary
- specific projects should tailor the vocabulary to their needs (e.g. using only several languages, specific data types etc.)
inventaire uses Elasticsearch to store and use filtered data, so that e.g. not *all* humans are scanned for author fields, but a specific subset
- Difficulties and => suggested workarounds
- typed search
- inconsistent data => hacked by having a whitelist of synonyms that should link to a single entity
- expensive SPARQL queries => use cache
- illustrations are not always available for free (not available on Commons) => try to find images on social networks and hide from tha police
A scoring system is mandatory: there are many Victor Hugo's => https://inventaire.io/search?q=victor%20hugo
people usually seach for *the one and only* Victor Hugo; solution is being implemented by assessing the incoming links score
Whats in the future of inventaire.io :
- browse inventories by subcategory (genre, author, subject etc.)
- build a suggestion engine that can create new claims
- disambiguate/merge 2 items from different users into one item displayed with a list of owners
- reviews
- CC license
- improving Wikidata using inventaire
- How to improve inventaire
- improve data
- discuss features: roadmap.inventaire.io
- open issues: git.inventaire.io
- translate: translate.inventaire.io
- share the word
Questions / Answers[edit]
Q: Are edits made on inventaire reflected on WD? A: Yes.
Q: Can you source them in inventaire's edit feature? A: No.
Q: For the application to work, do the books have to be on WD? A: No, users usually do not know about WD; and WD community is the one to decide what is good for them. inventaire has a local database, separate from WD
Q: Do you have entities that are classifiable as different types (e.g. both series and edition)? A: Yes, it is a problem mitigated by the effort of cleaning the data
Q: Can you import from Goodreads? A: Yes, but the functionality is not ideal yet
Q: Can you import simply a list of ISBN? A: It is a feature request and may be implemented in future => https://trello.com/c/GX3VXMBr/120-isbn-batch-import
Q: Import from inventaire to WD, is it done from personal Wikimedia account, or does inventaire has its own shared account? A: personal account for now, because the database is quite immature and the edits are often done on a fail-and-retry approach